Scaling vision foundation models is limited by the quadratic cost of self-attention. Generalized Spatial Propagation Networks (GSPN) provide a linear-time alternative that propagates context directly on the 2D grid and removes positional embeddings, but have not been scaled to foundation-level training. We present Compact GSPN (C-GSPN), a ViT block with a compressed propagation space that preserves accuracy while cutting propagation latency by nearly 10×, complemented by lightweight projections and fused CUDA kernels for further efficiency. To pretrain at scale, we use a two-stage distillation scheme with module-wise supervision and end-to-end alignment. In a representative 1K configuration (batch 32, C=1152), C-GSPN yields up to 2× speedup, while maintaining competitive zero-shot accuracy and improving segmentation by +2.1%. Extensive experiments and ablations confirm that the proposed compression and two-stage distillation are key to achieving strong transfer while substantially reducing compute, offering a practical path toward subquadratic vision foundation models.
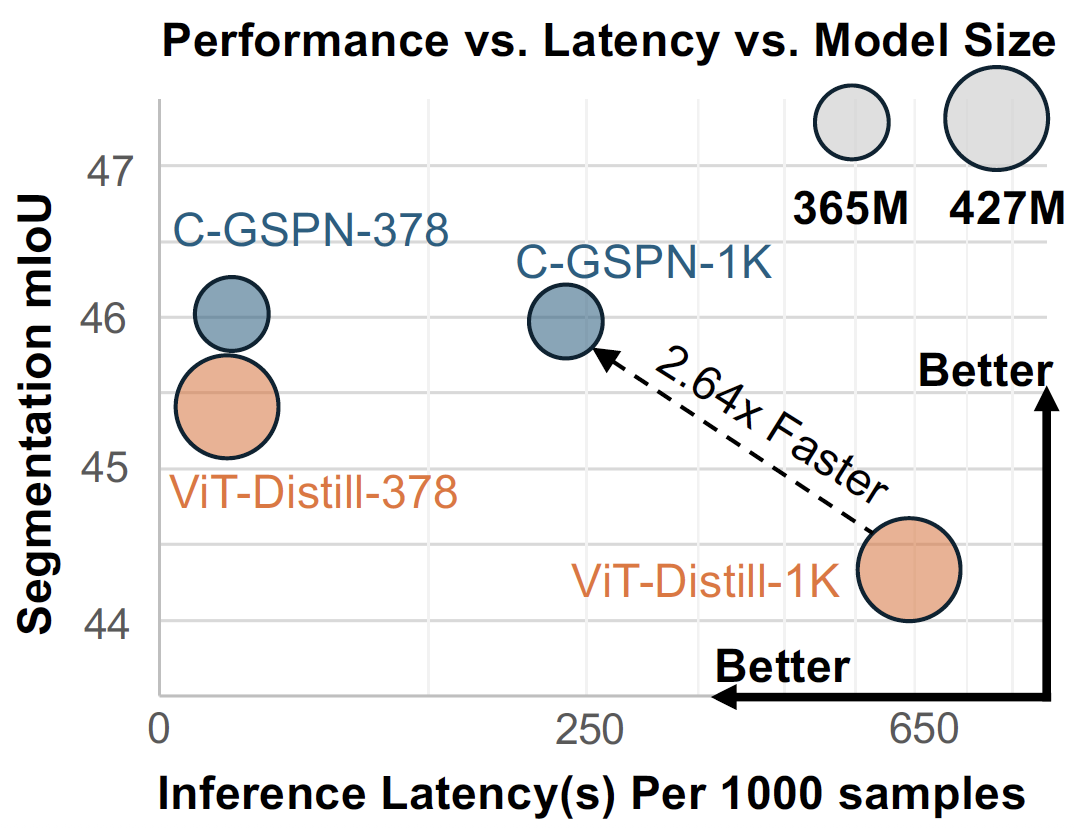
C-GSPN achieves 2.64× faster inference while maintaining competitive segmentation performance.
Scaling vision foundation models is bottlenecked by self-attention's quadratic O(N²) cost, which explodes with higher resolutions and limits memory, latency, and high-resolution deployment. Generalized Spatial Propagation Networks (GSPN) offer a linear-time alternative, propagating features directly on 2D grids with O(√N) effective depth and no positional embeddings. However, original GSPN faces CUDA limitations that hinder scaling with increasing batch and channel sizes, and it has not yet been adapted to foundation-level data volumes and model scales.
We introduce Compact GSPN (C-GSPN), which leverages distillation for effective pretraining while enabling efficient scaling of subquadratic architectures to vision foundation models through compressed latent-space propagation, redesigned projections, and fused CUDA kernels—yielding ~10× latency reductions and addressing channel and batch bottlenecks for practical high-resolution encoders.
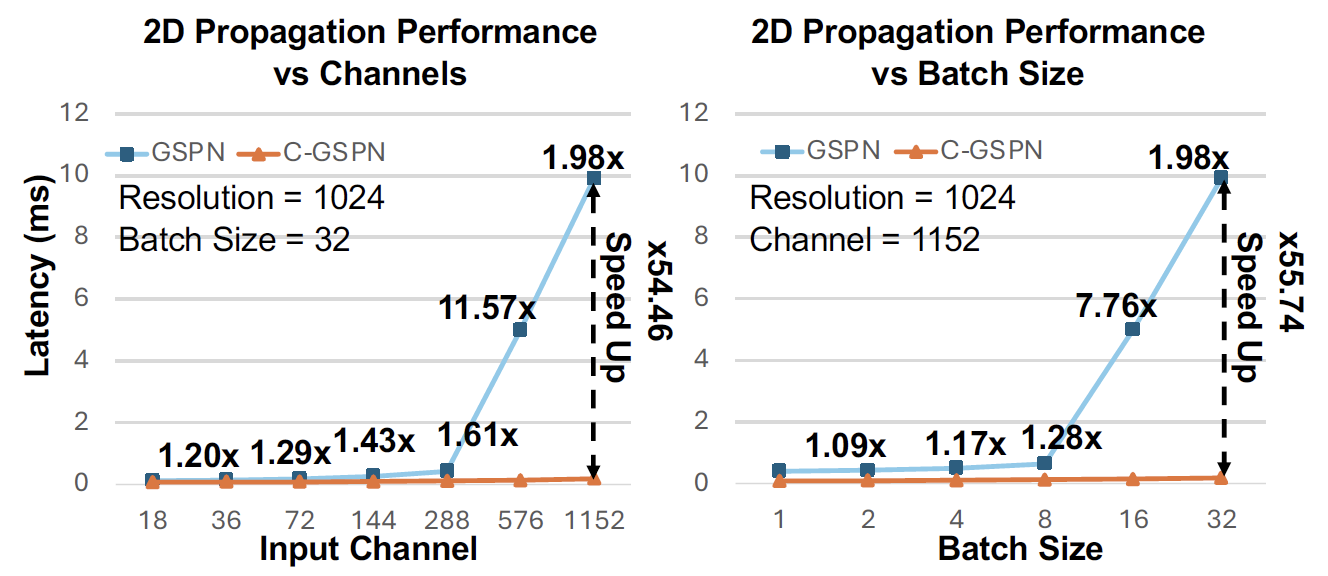
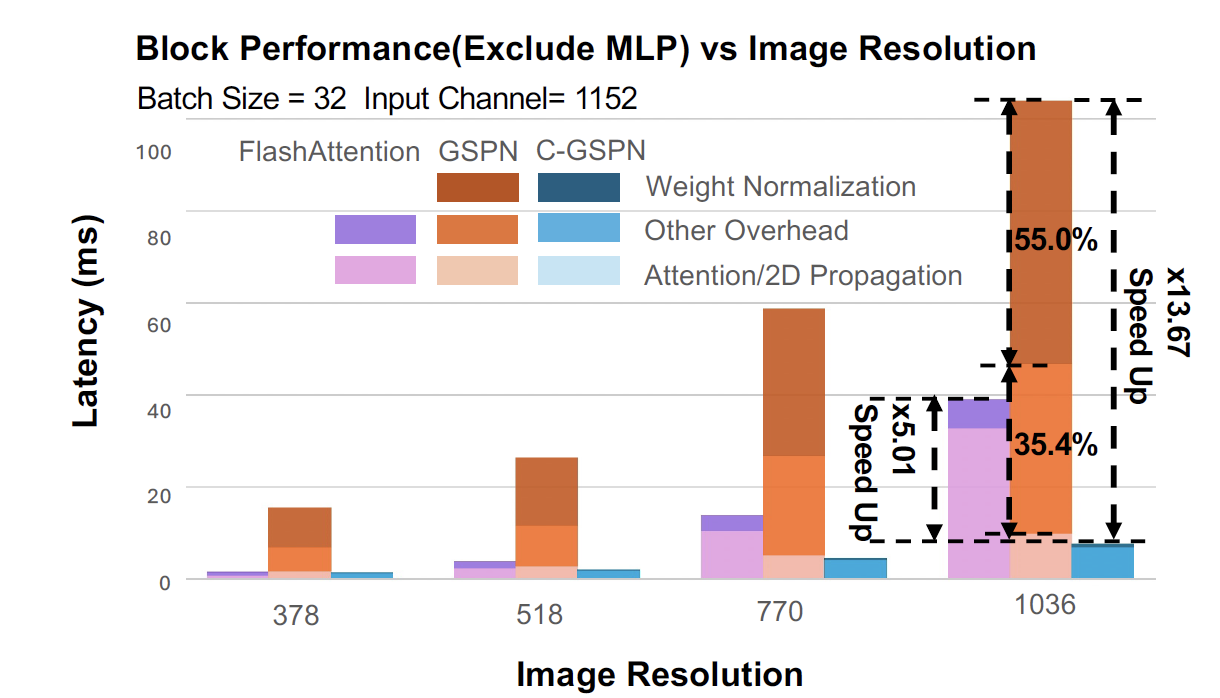
Left: C-GSPN demonstrates significant speedups across different channel dimensions and batch sizes. Right: C-GSPN achieves 13.67× speedup over FlashAttention at 1036 resolution.
Our method introduces three key innovations to enable efficient scaling of spatial propagation networks to foundation models: (1) Compressed latent-space propagation that reduces computational overhead by nearly 10×, (2) Unified CUDA Kernel for Overhead Reduction, (3) A two-stage distillation scheme with layer-wise pretraining and end-to-end alignment for effective foundation-level training, and (4) Progressive high-resolution transfer with feature interpolation for efficient adaptation under limited computational budgets.
Overview of the Compact GSPN method, showing the architecture design, two-stage distillation strategy, and high-resolution transfer approach.
C-GSPN achieves significant latency reductions compared to both FlashAttention and the original GSPN across different resolutions. The compression and optimization techniques enable practical deployment at higher resolutions.
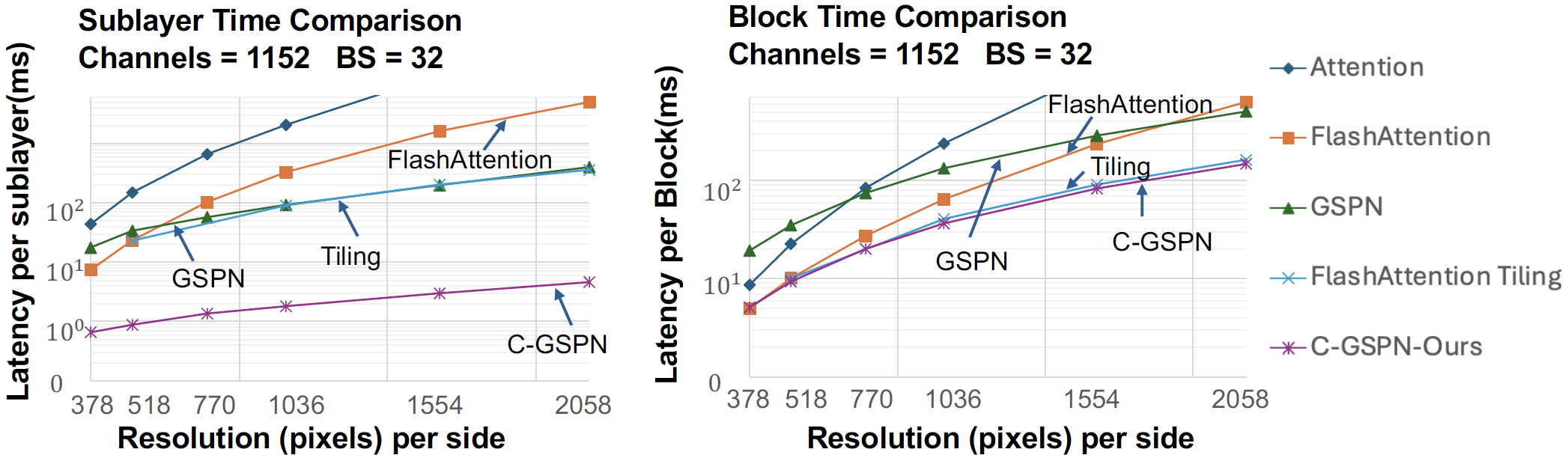
Left: C-GSPN achieves 10× lower sublayer latency compared to GSPN across resolutions. Right: C-GSPN maintains consistently low block-level latency, approaching FlashAttention Tiling efficiency.

Detailed latency and throughput measurements for sublayer, layer, and block levels across different resolutions.
When transferring to higher resolutions with limited computational budget, C-GSPN demonstrates strong performance consistency. With knowledge distillation, C-GSPN achieves 2.64× speedup over ViT-Distill while maintaining consistent segmentation performance across multiple resolutions (378, 518, 756, 1036).
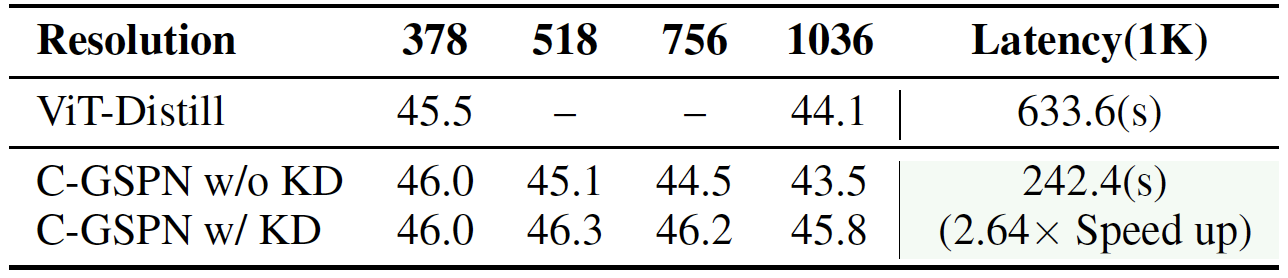
C-GSPN with knowledge distillation (KD) achieves 2.64× speedup over ViT-Distill while maintaining consistent segmentation performance across resolutions, demonstrating effective high-resolution transfer with limited computational budget.
C-GSPN maintains competitive performance on both classification and dense prediction tasks. Through two-stage distillation, C-GSPN achieves 81.3% zero-shot accuracy (vs. 82.2% ViT-Distill baseline) while significantly improving segmentation performance by +2.1% on ADE20K compared to the baseline.

C-GSPN achieves competitive results across classification and dense prediction tasks with 14% fewer parameters than GSPN, demonstrating effective knowledge distillation and architectural efficiency.
Our work builds upon the foundation of spatial propagation networks for vision tasks.
Generalized Spatial Propagation Network (GSPN) introduces a linear attention mechanism optimized for multi-dimensional data that directly operates on spatially coherent image data. Our Compact GSPN extends this work by introducing compression techniques for efficient foundation model training.
GSPN-2: Efficient Parallel Sequence Modeling builds upon GSPN with further optimizations for efficient parallel sequence processing.
@article{park2021nerfies,
author = {yitong jiang, Collin McCarthy, Hongjun Wang, Hanrong Ye, Qi Dou, Tianfan Xue, Jinwei Gu, Jan Kautz, Hongxu Yin, Pavlo Molchanov, Sifei Liu},
title = {Compact GSPN: Scaling Spatial Propagation to Vision Foundation Models},
journal = {arXiv},
year = {2026},
}